About the Project
The Problem
We have an unprecedented ability to generate data. Unfortunately, the pace of analysis has not caught up. Mountains of data are available publicly just waiting to be analyzed, if we could only allocate the time and resources to (1) find it, and (2) integrate it into a usable format.
Data Repositories
Funding agencies increasingly require data to be shared publicly. However, repositories are often domain-specific and relevant data for a new project can be scattered across a half dozen repositories, each with their own authorization process.
New multi-center research consortia also require data to be harmonized across multiple data collection sites, and this process can take a sizable portion of a project's budget, time, and staff. This time could be better spent performing analyses!

Our Approach
We want scientists to spend less time searching, accessing, and integrating data. That way they can spend more time doing the thing they were trained to do: make discoveries.
MetaMatchMaker will use natural language processing in machine learning to help automate finding and accessing data. Users can search for topics by keyword and apply filters. Results show details about datasets like sample size, demographics, and other key information. This way you'll know if the data we found for you is appropriate to incorporate into your analysis.
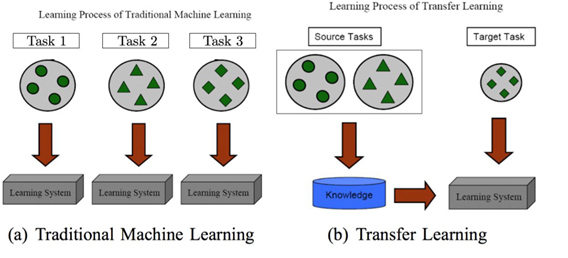
Transfer Learning
The core of our approach stems from recent advances in machine learning using pretrained learning models, or also known as transfer learning. In traditional machine learning, training data are used to create a model for a specific task. When a new task is needed, new training data are used. In transfer learning, the insights gained from the initial task are shared with training of the new task. In this way, a deep learning model can iterated to become more robust and more usable.